Multimodal AI
Articles about multimodal artificial intelligence, vision-language models, and multimodal understanding.

GPT Image 2 vs Gemini 3 Pro Benchmark 2026
Compare GPT Image 2 vs Gemini 3 Pro across 8 categories. Gemini is 4x faster, GPT has better detail. Full results with outputs.
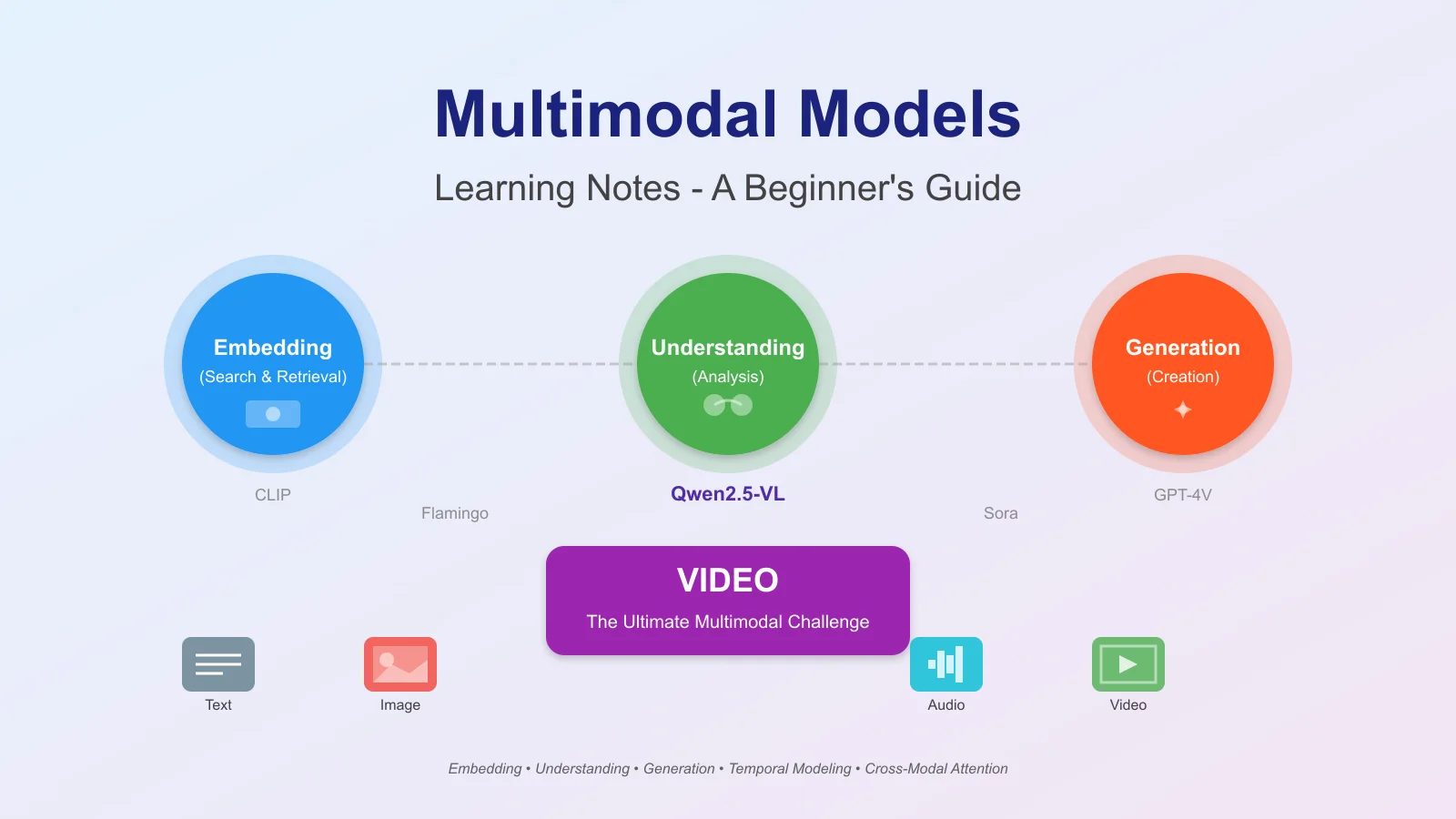
Multimodal Models Learning Notes - A Beginner's Guide
Learn multimodal AI from scratch. Embedding, understanding, and generation paradigms with CLIP, Qwen2.5-VL, and Sora examples.

Amazon Nova Video Analysis: Object Detection (2026)
Analyze video with Amazon Nova on AWS Bedrock — working TypeScript for object detection, bounding boxes, and S3 videos up to 1GB.

Best AI Video Search Tools 2026: 10+ Tested
Which AI video search platform wins? TwelveLabs, Google Video AI, and 8 open-source tools tested on accuracy, speed, and cost.
DeepSeek VL2 vs Janus in 2026: 4 Multimodal Models Compared
DeepSeek shipped 4 open-source multimodal models in 10 months. Compare VL2 MoE architecture vs Janus unified encoding. Benchmarks show which beats GPT-4V on vision tasks.